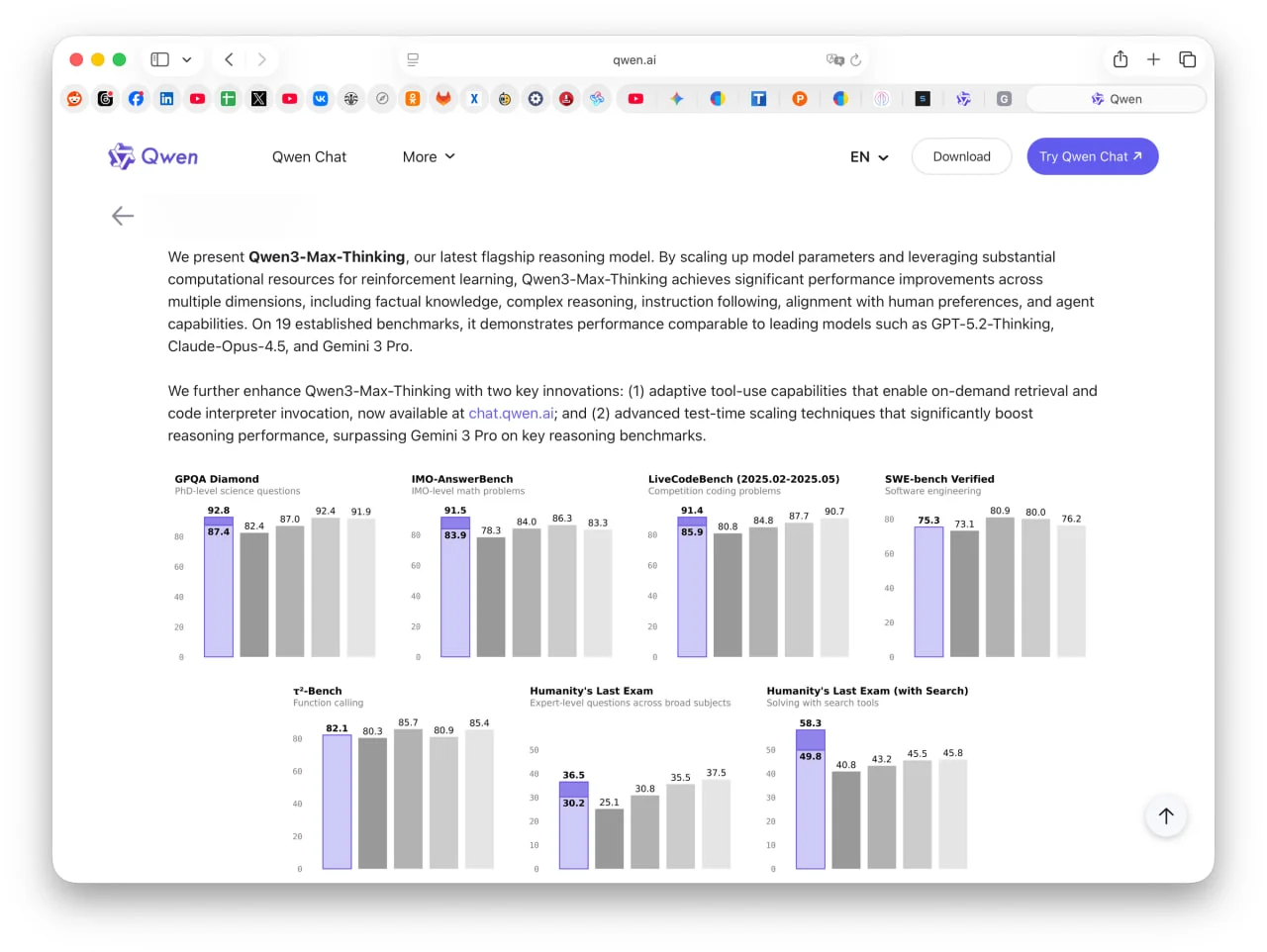
Alibaba выкатила Qwen3-Max-Thinking, и на её фоне GPT-5.2 с Claude-Opus-4.5 выглядят слегка отстающими в развитии. В бенчмарках - тотальный разнос (особенно в Arena-Hard), а вместо тупого перебора вариантов модель теперь «умнеет» прямо в процессе диалога, накапливая инсайты.
Самое забавное: этот «китаец» настолько всеяден, что маскируется под конкурентов, поддерживая API и OpenAI, и Anthropic (даже Claude Code работает нативно). GLM 4.7 теперь официально антиквариат.
Тестим, пока дают: chat.qwen.ai :)
Русский ИТ бизнес

Русский ИТ бизнес
28 янв 2026 20:37
Alibaba выкатила Qwen3-Max-Thinking, и на её фоне GPT-5
Комментарии (7)
Они просто играют цифрами. Для прорыва хватает 1-2%.. По факту промпт их даёт в легкую!
Просто попытка перетянуть лоха к себе..
Элементарную ошибку исправить не может, как не детализируй промпт. Gpt 5.2 mr с первого раза.