Вот на Reddit выложили анонс - теперь можно дообучать DeepSeek-OCR прямо в их среде. Смотрю и думаю: наконец-то OCR-модели стали доступнее для кастомизации.
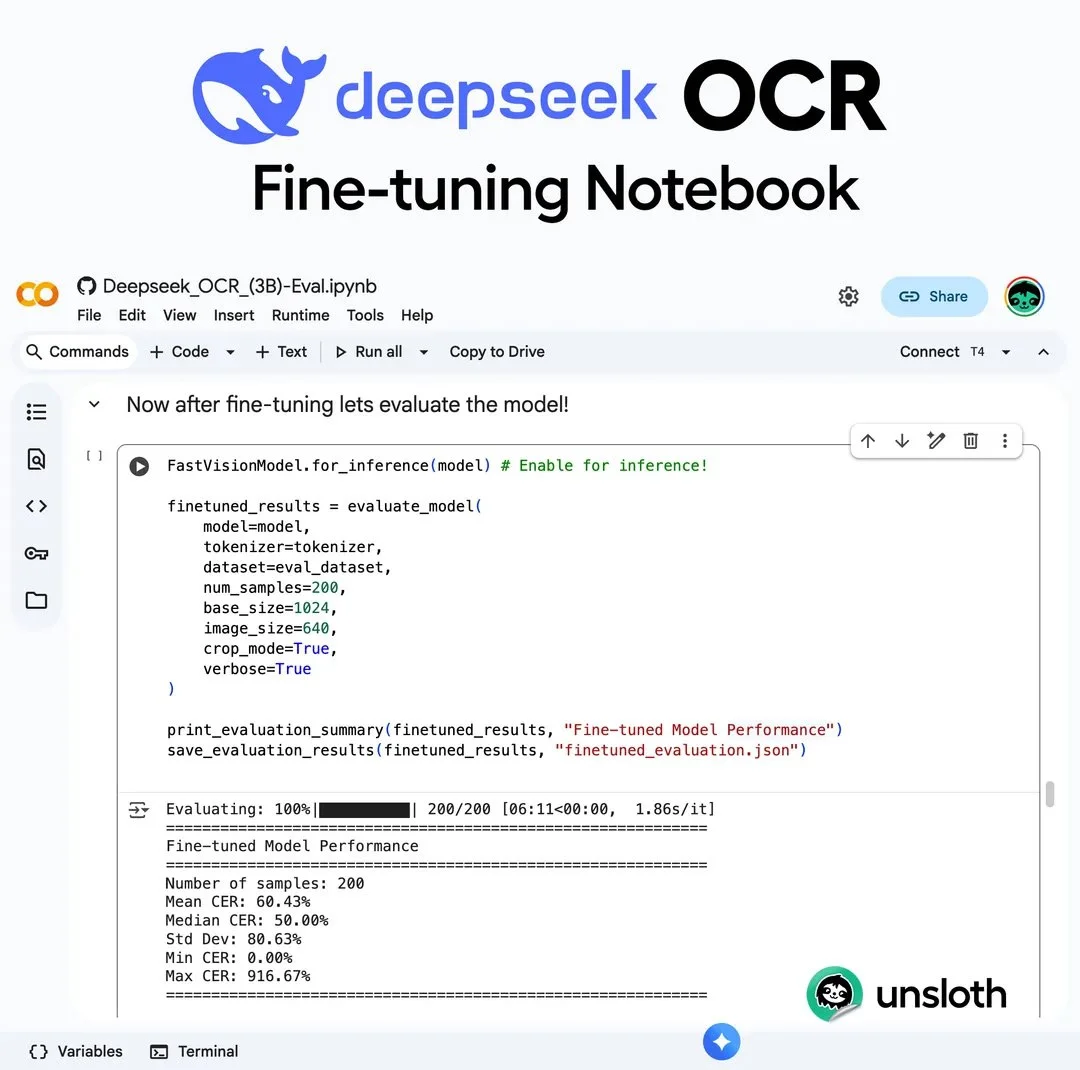
Проблема-то в чём: стандартные OCR часто плохо понимают специфичные шрифты, рукописный текст или редкие языки. А тут предлагают быструю настройку модели всего за 60 шагов - и уже есть результаты на персидском датасете :)
Что получилось у команды Unsloth:
- Улучшили языковое понимание модели на 89%
- Снизили ошибки распознавания символов с 149% до 60%
- Выложили бесплатные ноутбуки для обучения и оценки
- Модель уже доступна на Hugging Face
И ведь многие сталкиваются с кривым распознаванием текста, но молчат - особенно в нишевых проектах.
А вы как думаете - это действительно прорыв в кастомизации OCR или просто очередной инструмент, который усложнит жизнь разработчикам?
Русский ИТ бизнес

Русский ИТ бизнес
6 ноя 2025 09:10
а с этим могут быть проблемы