Наконец-то! ИИ, который понимает документы, а не просто копирует текст
Знакомо, когда загружаешь PDF в нейросеть, а на выходе получаешь бессвязную простыню текста без структуры? DeepSeek представил решение, которое действительно работает...
Что умеет новый DeepSeek-OCR:
📄 Восстанавливает структуру документа - заголовки, списки, таблицы
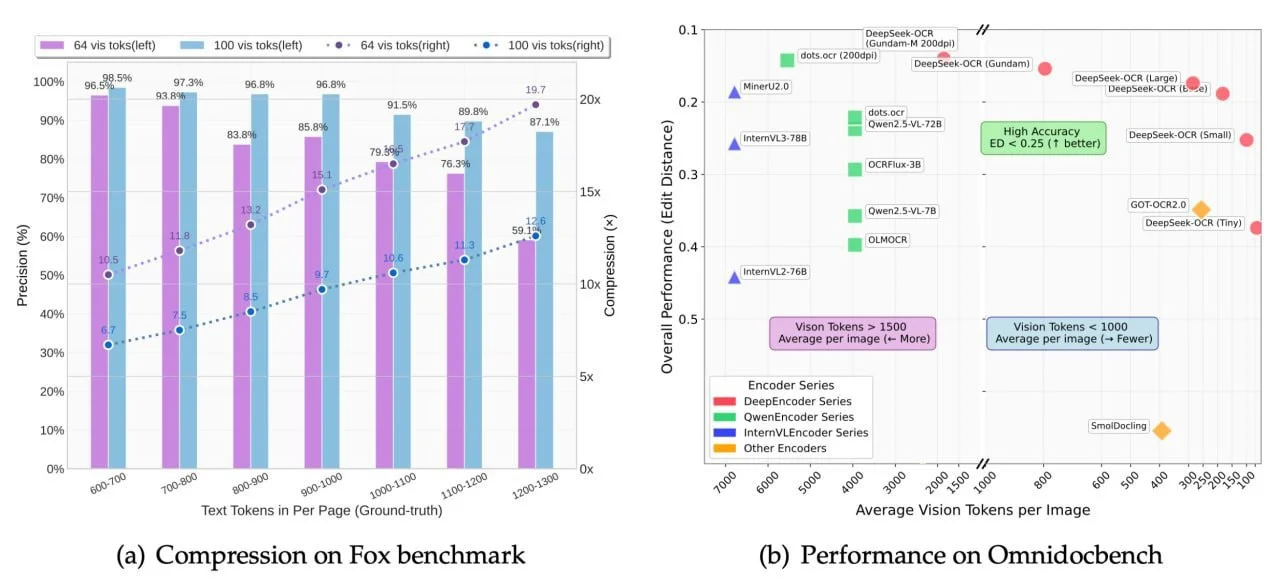
🎯 Точность 97-99% даже с минимальными ресурсами
⚡️ Сжимает данные в 10-20 раз - дешевле и быстрее
🦸 Режим Gundam - сам делит сложные документы на части
Самое крутое:
- Открытая лицензия MIT - можно использовать бесплатно
- Результат в Markdown - идеально для дальнейшей работы с ИИ
- На тестах обгоняет тяжелые модели типа Qwen
А вы уже пробовали новые OCR-модели? Или до сих пор мучаетесь с старыми системами, которые путают таблицы с текстом? :)
Делитесь в комментах - кто какими инструментами для распознавания документов пользуется? Мы это для RAG применим, хотя временно команда отвлеклась.
Русский ИТ бизнес

Русский ИТ бизнес
27 окт 2025 14:02
Плюс вот эти иконки: 🎯, ⚡️, 🦸 - их только боты ставят и рекламщики. Очевидно, что бот писал