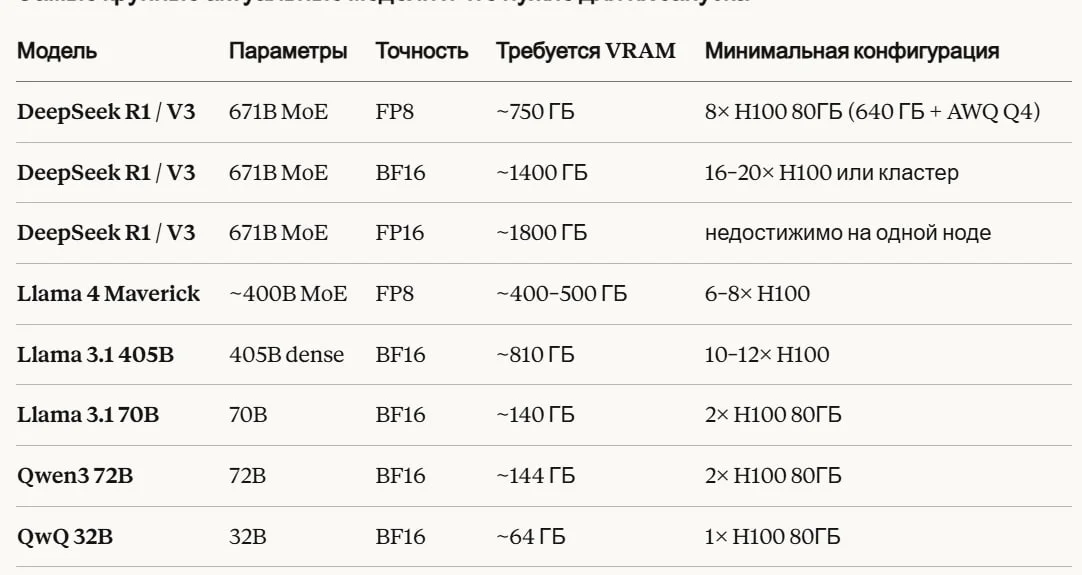
Расчет по VRAM для более менее полноценных моделей LLM
Конфигурации для DeepSeek R1 671B
Минимум (с квантизацией Q4/AWQ):
8× H100 80ГБ = 640 ГБ суммарно → 671B в AWQ Q4 (~400 ГБ весов) влезает
Скорость: ~33 tok/s при одном пользователе, ~600 output tok/s при 100 concurrent users
Комфортный вариант (FP8 native):
8× H200 141ГБ = 1128 ГБ → 671B FP8 (~750 ГБ) с запасом на KV cache
Скорость: ~821 output tok/s (vLLM benchmark)
Альтернатива без GPU (экзотика):
Сервер с 768+ ГБ DDR5 RAM + llama.cpp → 671B Q2 работает, но ~1–2 tok/s
@DevsRoot

Бесконечный Цикл
20 фев 2026 08:04
Расчет по VRAM для более менее полноценных моделей LLM
Комментариев пока нет.