Почему LLM типа ChatGPT лучше работают на английском, чем на русском? Легкий ликбез.
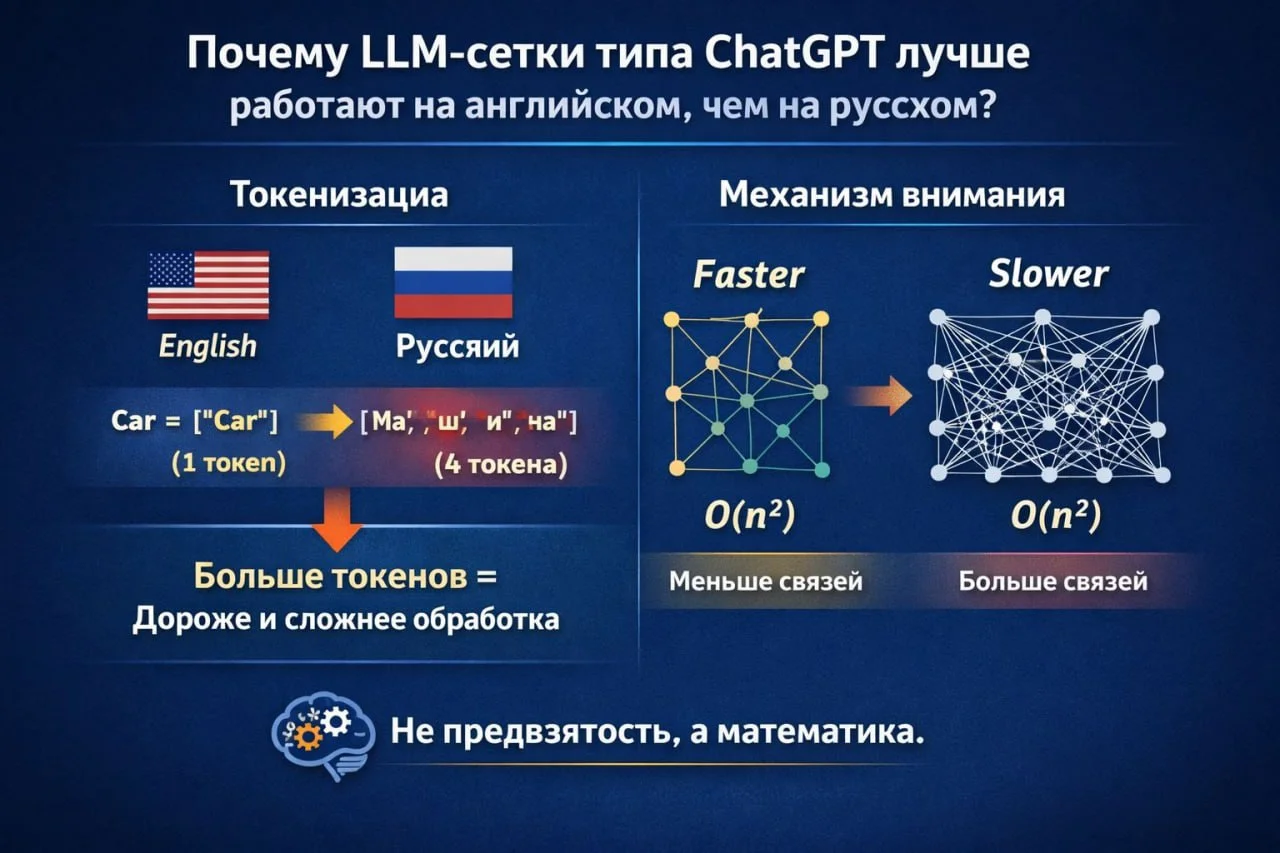
Ключевая причина - токенизация.
Для человека логическая единица - слово. Для модели - токен.
Чтобы получить токены, текст прогоняется через токенайзер, который разбивает слова и символы на подстроки и сопоставляет им числовые идентификаторы.
Модели обучены преимущественно на английском языке, потому что именно на нём представлены большие, качественные и структурированные массивы данных. Дополнительно английский язык проще с точки зрения токенизации: слова короче, морфология беднее, больше повторяющихся корней, отсутствуют падежи. В результате английские слова чаще кодируются 1–2 токенами, тогда как русские 4–6.
Далее вступает в работу механизм внимания (attention), который параллельно распределяет веса между токенами и строит связи. В фразе «у меня сломалась моя старая тойота» человеку очевидно, что сломалась машина, а не я или абстрактный объект. Модель же должна распределить внимание между всеми токенами, чтобы прийти к тому же выводу.
Attention имеет квадратичную вычислительную сложность по числу токенов. Итого: больше токенов → больше связей → выше вычислительная нагрузка и больше шума. Меньше токенов - дешевле, стабильнее и точнее обработка.
Как-то так...
Русский ИТ бизнес

Русский ИТ бизнес
8 янв 2026 19:35
Руссяий - это, кстати, чей язык?
Профиль пациента > Выбор уже выписанного и получаемого лекарства > Проверка медкарты с анализами > Анкетирование состояния