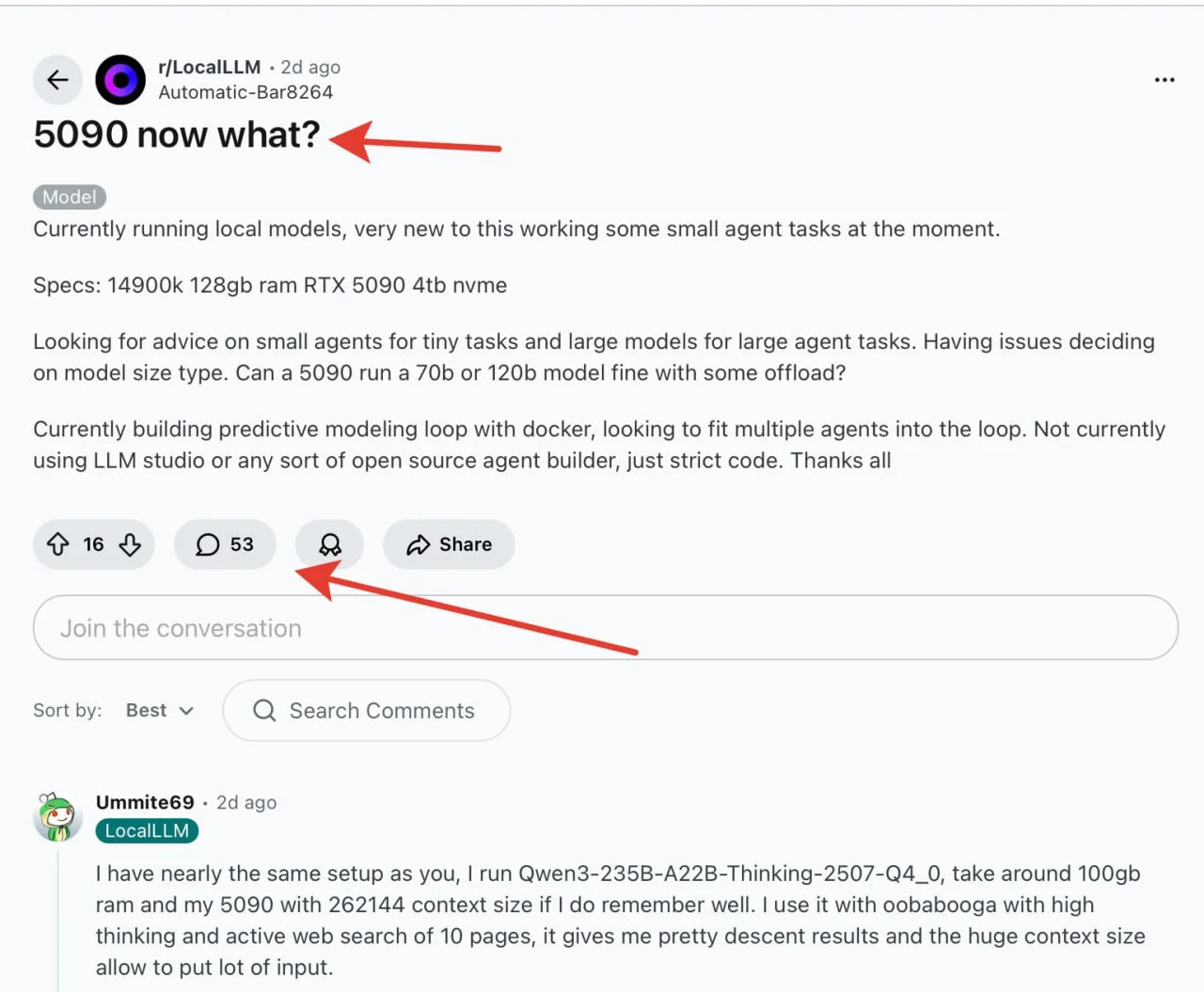
На реддите парень с топовым железом -RTX 5090, 128GB RAM и процессором 14900k спрашивает, как эффективно использовать эту мощь для локальных ИИ-агентов. Он хочет запускать как небольшие модели для простых задач, так и гигантов типа 70B-120B параметров.
В комментариях опытные пользователи объясняют, что даже с 5090 придется идти на компромиссы:
- 70B модели будут работать с оффлоудом на CPU, что замедлит генерацию
- Кто-то запускает Qwen3-235B, загружая 100GB в оперативку
- Важно балансировать между размером модели, контекстом и скоростью
Особенно отмечают, что многие покупают такое железо для гейминга, а ИИ-задачи становятся оправданием покупки.
ссылка если хотите почитать детали. Вообще советов много.
Сами кто пользуется локальными моделями? Не пойму одного - это же просто хобби. Ну зачем они нужны?
Вот смотрите, тут делятся скоростью генерации (даже переводить не стал) "Speed: Output generated in 32.48 seconds (4.40 tokens/s, 143 tokens, context 89, seed 2103593798)"
Ну и нафига вам такое надо? А я ведь знаю людей, которые еще умудряются обучать (!) ИИ на домашних игровых ПК.
Русский ИТ бизнес

Русский ИТ бизнес
3 ноя 2025 10:32
-
 Возможно нужны, чтобы персональные данные в сеть не утекали. Хотя можно обезличивать при работе с такими данными.
Возможно нужны, чтобы персональные данные в сеть не утекали. Хотя можно обезличивать при работе с такими данными. -
 ОТретушировать домашний порноархив например с SD да много применений можно найти, было бы желание
ОТретушировать домашний порноархив например с SD да много применений можно найти, было бы желание -
 Мне нравится, как Макс постоянно опускает такую маленькую ненужную деталь, как квантование. Уже столько постов однотипных с редита обмусолил, хоть бы поинтересовался для чего и зачем
Мне нравится, как Макс постоянно опускает такую маленькую ненужную деталь, как квантование. Уже столько постов однотипных с редита обмусолил, хоть бы поинтересовался для чего и зачем-
 ты же комент родил, значит Макс свою задачу выполнил. Мы тут как бактерии, а он время от времени вбрасывает сюда агар-агар, чтобы мы ели, какали, размножались, создавали активность
ты же комент родил, значит Макс свою задачу выполнил. Мы тут как бактерии, а он время от времени вбрасывает сюда агар-агар, чтобы мы ели, какали, размножались, создавали активность-
Был бы смысл, если была рекомендательная система, а так ...
-
да кому тебя бациллу рекомендовать то
-
-
-
-
 Как раз обучение вполне себе оправдано, пускай медленно, но локально обучил на своих данных и приватно по ним базаришь тихонько.
Как раз обучение вполне себе оправдано, пускай медленно, но локально обучил на своих данных и приватно по ним базаришь тихонько. -
 Перс данные, обезличивать ну нет смысла какие-то большие документы
Перс данные, обезличивать ну нет смысла какие-то большие документы -

 Он ещё спрашивает зачем
Он ещё спрашивает зачем