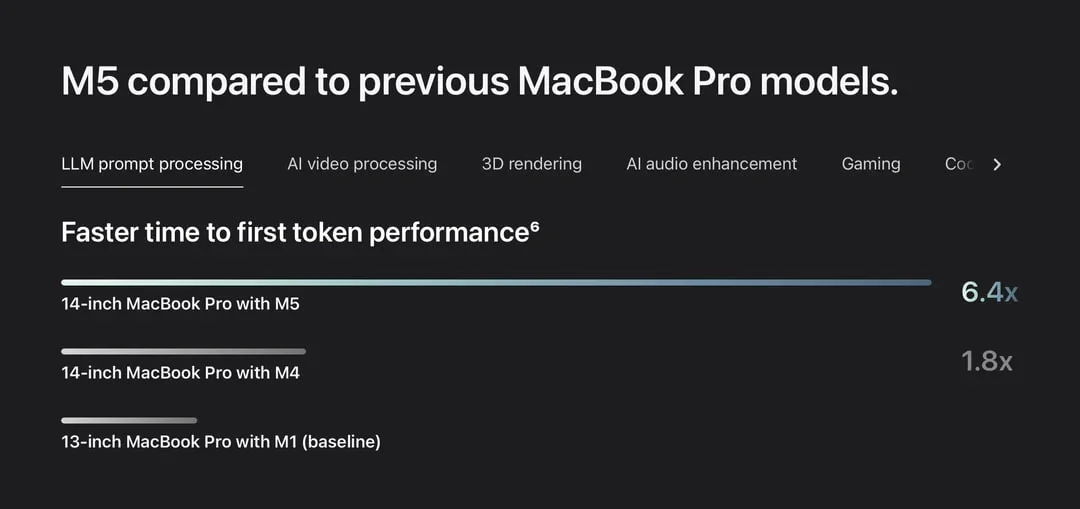
Для апологетов ИИ - новый чип Apple M5 в 6 раз быстрее текущего в части генерации текста (до первого токена). Что это значит? Как минимум, запуск локальных ИИ будет проще и работать они будут быстрее.
Но скажу так - чем сильнее надувается пузырь ИИ, тем дешевле будут токены и меньше смысла в локальных моделях, если их можно за копейки покупать на рынке.
Русский ИТ бизнес

Русский ИТ бизнес
15 окт 2025 22:17
Комментарии (1)